

How To Use Multicast With Ip Cameras
Abstract
This white paper describes a multicast architecture design for IP surveillance networks that crave stringent SLAs on fast convergence, stability and scalability.
Introduction
IP multicast video surveillance deployments are growing in popularity due to awarding requirements and the demand for bandwidth efficiency. Even so, such deployments are often challenged with the following mandatory requirements:
● Fast multicast convergence
● Error tolerance
● Scalability
Cisco StackWise ® Virtual is well-suited to meet these requirements, and the high performing Cisco Catalyst ® 9000 family further boosts overall performance.
Multicast IP video surveillance requirements
The following are the three near critical requirements for multicast-based IP video surveillance:
Fast convergence: This is mandated for both security and compliance reasons, considering some business entities may need to close down if monitoring and recording are impacted due to a surveillance blackout. Every bit service availability is dictated by fast multicast convergence, yet multicast convergence tin can happen merely afterwards unicast reconvergence, this requirement poses the greatest challenge to nigh multicast deployments.
Error tolerance: The network should exist able to respond in a deterministic manner to any kind of failure, including link-level, hardware component, and chassis failures or even a combination of all these.
Scalability: A good multicast network must always support growth of 30 to fifty per centum from the initial calibration without having to undergo a cardinal change in design.
Components of IP multicast video surveillance systems
Application characteristics
In a typical IP video surveillance environment, the surveillance cameras serve every bit the source of the multicast. Depending on the scale of the business, the number of cameras can range from a few hundred to tens of thousands. On the receiving end of the multicast data are the recorders or storage systems. Most of the time there volition be 2 independent storage systems in place for recording redundancy and compliance purposes. In that location are also operators who need to see the photographic camera footage in real time for monitoring purpose, and hence these operators also function as multicast information receivers.
IP multicast routing protocols
Generally, multicast routing protocols tin exist grouped into either intradomain or interdomain protocols. For a smaller-scale network, a single multicast domain should suffice for ease of management. However, in larger networks, depending on their topology, information technology sometimes makes more sense to segment the network into different multicast domains, as well known as Autonomous Systems (Equally). These domains then commutation multicast source and routing information via an interdomain multicast protocol to facilitate the ability of the receivers in ane domain to subscribe to the information sources in another domain.
Multicast routing protocols
There are many variants of Protocol-Independent Multicast (PIM), but PIM-SM and PIM-SSM are more commonly deployed in surveillance networks.
● PIM-SM: PIM Thin Fashion (PIM-SM) is a pull model, with multicast data being delivered just to hosts that explicitly asking it. It is more often than not deployed together with Anycast RP, which uses Multicast Source Discovery Protocol (MSDP) to exchange multicast information between Rendezvous Points (RP). PIM-SM volition be used here as an example.
● PIM-SSM: PIM Source-Specific Multicast (PIM-SSM) is another viable option in which users are allowed to specify the multicast source in which they are interested. Withal, as PIM-SSM requires Cyberspace Group Management Protocol (IGMP) v3 to work, it is less often seen in video surveillance networks.
● PIM-BIDIR: Bidirectional PIM (PIM-BIDIR) is a viable choice, although it is nigh effective in cases where any multicast node tin become both source and receiver.
● MSDP: MSDP, as defined in Experimental RFC 3618, is widely used to advertise and share active multicast source information between different RPs in different domains. It besides acts equally a fundamental protocol in Anycast RP to achieve load balancing and back-up of two or more than RPs in a single PIM-SM domain.
IP multicast rendezvous point technology
An RP is configured on a router, and it acts as a shared root for a multicast shared tree in a multicast domain. Information technology is important to choose the correct RP deployment method for different utilize cases. For example, questions such as "Does RP information demand to be configured on every router?" "Does information technology back up RP redundancy?" "Does it support IPv4/IPv6?" etc. must be taken into consideration.
Although several methods are available (Static RP, Auto-RP, Anycast RP, Phantom RP, Bootstrap Router [BSR], Embedded RP), only Static RP and Anycast RP will be considered here, for the following reasons:
● Simplicity (Static RP works fifty-fifty in big-calibration networks)
● Subsecond convergence is a must (Car-RP and BSR could incur boosted time)
● The topology for IP video surveillance networks seldom changes
● They offer back up for third-party devices
Static RP
With Static RP, the RP address is configured on every multicast router in the domain, together with the multicast group range for that RP if necessary. This is especially useful if the multicast domain does not have many RPs, and also if the RPs exercise not change often. However, Static RP itself does not provide any load balancing and back-up to the multicast domain. This can be overcome by combining Static RP with Anycast RP.
Anycast RP
Anycast RP is an intradomain deployment method that uses MSDP to provide RP redundancy and load-sharing functions. Two or more RPs are configured with the same IP address, ordinarily a /32 host address, on their loopback interfaces. This RP accost will exist configured on all the multicast routers in the domain. With an Interior Gateway Protocol (IGP) in place, the multicast sources will select and register to the RP that is closest to them, which then uses MSDP to exchange information about the active sources in the domain with its peers (other RPs).
Subsecond multicast convergence
At that place are a few multicast enhancements that will help in achieving subsecond multicast convergence. To enable this level of convergence, the new mechanism will need to process information such as hello packets arriving at intervals measured in milliseconds. As the network scales in multiple dimensions, this volition drive upwards the CPU usage of the PIM router, and hence any device with low CPU power will not be able to process the information. In the worst case, the device may assume that the PIM neighbor is disconnected if information technology cannot process the relevant packets in time, causing more false positives in the network that directly impact complete network stability. The trade-off betwixt subsecond convergence and college CPU cycles must hence always be examined thoroughly.
Here are some points to annotation when considering these enhanced features:
● Attempt out the mechanism in the lab earlier applying it to the production network.
● Outset leave the features with their default values, so tweak them accordingly.
● These enhancement features may non show any significant improvement in a small-scale network.
● Not every platform and software image supports all of these features, or a subset of them.
The following section describes a few of the more commonly used PIM-specific and non-PIM-specific features to help accomplish subsecond convergence.
PIM-specific considerations
PIM router query message interval
By default, a PIM hello parcel is transmitted on each PIM-enabled interface every 30 seconds. A PIM hello is used to find PIM neighbors and is also used to decide the Designated Router (DR). This characteristic enables a router to send PIM hellos more ofttimes. The default mechanism dictates that a PIM neighbor is considered downward after 3 sequent missed messages, or 90 seconds. By adjusting this setting to a value in milliseconds, it can aid in discovering unresponsive PIM neighbors more quickly, allowing a router to implement subsecond failover.
ip pim query-interval period [msec]
In a typical IP video surveillance network, this setting tin be changed to a lower value. Before adjusting these timers, information technology is imperative to consider the false-positive impact when a PIM router is deployed with organization-level redundancy using Stateful Switchover (SSO) engineering science. The route processor switchover typically takes several seconds to gracefully restart the control-plane process simply retains the forwarding information. If the PIM bulletin timers are reduced below these values, then during planned or unplanned failure, the PIM adjacency may time out and be reset past a peering DR neighbor arrangement.
Triggered RPF checks and RPF failover
When a multicast package is received on the interface, the router looks up the multicast source address in the unicast routing table and determines the outgoing interface toward the source. If the outgoing interface is the same equally the interface where the multicast packet came in, the multicast packet passes the Reverse Path Forwarding (RPF) cheque and is accepted. Otherwise, the packets are dropped.
The periodic RPF check interval is 10 seconds by default. Yet, with Triggered RPF Check enabled, whatever changes in the unicast routing table will immediately trigger a check of RPF changes for multicast road (mroute) states. This reduces the convergence time for PIM, IGMP, and MSDP states. However, in a network environs that is experiencing unstable routing, this setting could crusade RPF checks to exist triggered constantly, making multicast routing even more unstable while at the aforementioned fourth dimension exhausting both the CPU and retentivity of the router. To avoid this, a "backoff" machinery is added to prevent a second triggered RPF check from occurring for a minimum length of time. If more routing changes occur during the backoff menstruation, PIM doubles the backoff menstruation until the routing becomes stable.
ip multicast rpf backoff minimum maximum [disable]
In a typical IP video surveillance network, the periodic RPF interval can be left at its default.
PIM SPT threshold infinity
When the multicast information starts to period along the merged tree of source RP and RP receiver, the concluding-hop router (DR for receiver) will by default trigger a Join message toward the source to switch over to the Shortest-Path Tree (SPT) for a more optimal routing. If this is successful, the last-hop router will then transport a Prune message to the RP for that detail ( * , G), and the RP will delete the link to the terminal-hop router from the outgoing interface list of (S,K) and send a Prune message to the source.
Generally, it is desirable to switch over to the SPT immediately for less latency. However, this is the instance only if in that location is no resources business organization in the network, because SPT requires more than memory than the shared tree.
ip pim spt-threshold { kbps | infinity } [group-list access-list]
In a typical surveillance network, the SPT threshold is commonly set at 0 kbps to ensure that the SPT takes over immediately after the subscriber receives the first information from the source.
Non-PIM-specific considerations
Equal-toll multipath routing
By default, the RPF for multicast traffic will cull the highest IP address if equal-cost multipath (ECMP) is bachelor, as described in RFC 2362. With this feature, load splitting (not load balancing) can exist distributed over the ECMP links based on the hashing algorithm using multiple tuples. Although information technology is possible to load-split based on either just the source address or the source address combined with the grouping address, they often end upwardly creating some other upshot chosen polarization, which prevents certain links in some topologies from being used effectively. To overcome this problem, a side by side-hop router accost tuple is added into the hashing mix for RPF interface selection so every bit to better split the load. If there are three ECMP links, these adjacent-hop addresses will exist used together with the source accost and the group in the hashing algorithm to separate the multicast traffic.
ip multicast multipath southward-g-hash next-hop-based
In a typical IP video surveillance network, it is debatable whether this characteristic should be enabled. Although IP multipath provides much better resiliency, information technology complicates the troubleshooting considering the multicast traffic will now menstruum through several paths instead of one. For a medium- to large-scale multicast network, if in that location are two ECMP links, and the load is evenly split up, when either link flaps, fifty percent of the multicast streams will need to fail over. All the same, if multipath is not deployed, then depending on where the ECMP link fails, the failover could hit 100 percent if the path that all streams go through went downwardly.
Also, when technologies such equally Multichassis EtherChannel (MEC) or Virtual Port-Channel (vPC) are used, multipath could further complicate the troubleshooting process. EtherChannel's Upshot Parcel Hashing (RBH) is some other event that needs to be taken into consideration, as described later.
IGP (OSPF)
The unicast IGPs are important because multicast routing protocols depend on RPF, which is based on a unicast routing tabular array. Therefore, multicast routing can converge only after unicast routing has converged. Depending on the topology, IGP timers can exist tuned aggressively to achieve the minimum routing convergence. This paper focuses on Open Shortest Path First (OSPF), with the following tuned accordingly to achieve unicast subsecond convergence:
● spf-showtime, spf-hold, spf-max-wait via "timers throttle spf spf-start spf-agree spf-max-wait"
The iii parameters interoperate to determine how long information technology takes for an SPF adding to be run after notification of a topology alter effect (inflow of a Link Land Advertizement [LSA]). On the arrival of the starting time topology notification, the spf-starting time or initial hold timer controls how long to await before starting the SPF calculation. If no subsequent topology change notification arrives (new LSA) during the concur interval, the SPF is gratis to run again as soon as the next topology change issue is received.
● lsa-commencement, lsa-hold, lsa-max-wait via "timers throttle lsa all start-interval hold-interval max-interval"
Tuning the SPF throttle timer can aid in improving the convergence of the campus network to within the subsecond threshold, but it is not sufficient to ensure optimal convergence times. Two factors bear on the ability of OSPF to converge: the time spent waiting for an SPF calculation and the fourth dimension spent waiting for an LSA to be received, indicating a network topology change. The presence of these delay timers, like the SPF timers, was based on a need to ensure the stability of the network and mitigate against OSPF thrashing in the event of a flapping link or other network problem.
● lsa arrival via "timers lsa arrival milliseconds"
In tuning the throttle timer decision-making the generation of LSAs, it is necessary to make a configuration similar to that of the throttle timer controlling the receipt of LSAs. The "lsa arrival" timer controls the rate at which a switch accepts a 2d LSA with the same LSA ID.
● carrier-delay
The link failure notification to upper-layer protocols such as OSPF is updated by default at two seconds, impacting unicast convergence fourth dimension and subsequently multicast convergence time. The network administrator can optimize failure notification mechanics without relying on protocol settings such equally hello and dead timers. Nosotros recommend setting the carrier-delay settings on a Layer 3 interface (physical or bundled) to firsthand notification without any delays, every bit shown below:
interface 10/y/z
<ip address> <mask>
carrier-delay msec 0
● At that place is no 1 set of values that fits every network. In our testing environment, near of the values are left at their defaults, as that is sufficient to achieve the targeted convergence time.
RP placement
Assuming a 3-tier core-distribution-access architecture, the RP should always be placed on the core layer of the network, the middle point betwixt sources and receivers. In small networks, the RP tin be an integrated role of the core layer organization and can as well exist placed almost the sources or receivers without much impact.
However, for larger networks, the cadre generally has the highest processing power and throughput considering all the traffic volition demand to traverse it. Therefore, depending on the scale of multicast traffic and also on the number of its sources and subscribers, either the RP tin be configured on the cadre or, alternatively, the control plane of the PIM RP tin can be decoupled to a pair of dedicated routers that are attached to the core. The latter will offload the core and dedicate information technology to loftier-speed data switching.
Placing the RP on either the distribution or access tiers is not recommended, since it might introduce suboptimal routing for multicast traffic. Besides that, those devices (distribution and access) need to be fortified, and placing the RP on them would hence defeat the purpose of this architecture.
Core network design requirements
The following listing consists of customer requirements seen in several similar deployments.
● Typical 3-tier network architecture – cadre, distribution, access.
● The network topology must be highly scalable to fully employ all its chapters to support futurity network, user, and application expansion growth of at least 30 to 50 percentage.
● The network must be able to back up 10,000 multicast Hard disk video cameras, each acting as a multicast source, with the frame charge per unit of 25 fps using H.264 (vi Mbps per stream).
● Each IP camera acts as a unique multicast source sending to a unique multicast grouping.
● PIM-SM is used as at that place is no IGMPv3 support in recording servers/hosts.
● Two recorder systems for redundancy purposes.
● Each recorder may receive a few hundred multicast streams.
● The recording systems as well as the surveillance network operators act every bit multicast receivers.
● Multicast routing should converge in the shortest time, preferably less than 2 or 3 seconds, if not subsecond, wherever possible to uphold service availability.
Main blueprint considerations
The following are a few design guidelines for achieving an IP multicast video surveillance network with fast convergence, fault tolerance, and scalability taken into consideration.
Link bandwidth
As fault tolerance is critical and prevails over the initial deployment cost, typically most of the IP video surveillance networks will adopt an undersubscription model, in which the last link remaining between the two network devices must be able to carry the required maximum throughput. Ports with line-rate or one:1 mode should also ever exist preferred over the not-line-rate ports.
Port-channel hashing (RBH)
EtherChannel is a link aggregation technology that is ordinarily used to bundle multiple private links into one logical link to increment the full bandwidth and redundancy.
Assuming that a port channel has "north" member links, information technology is ideal to distribute the traffic load evenly across all these links, if possible. An EtherChannel load-balancing algorithm can be based on many combinations, as shown below. How distributed the flows would be depends on which algorithm is configured. To achieve the best outcome, the well-nigh complicated combination of vlan-src-dst-mixed-ip-port is generally configured.
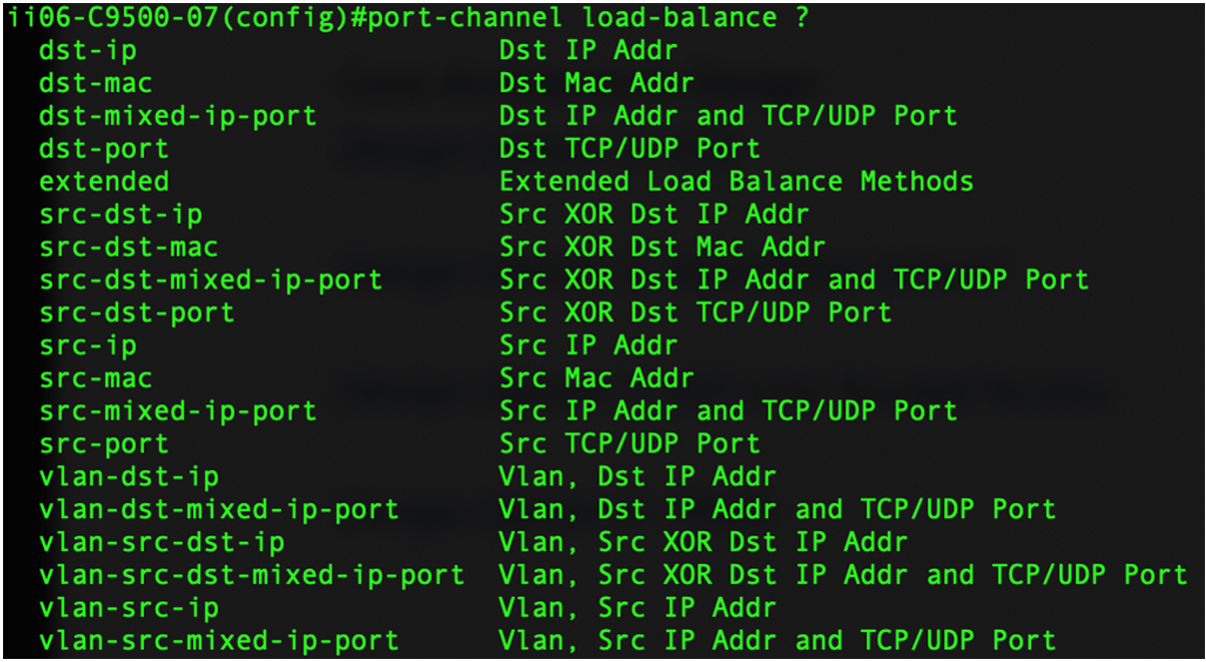
In older-generation Cisco Catalyst switches, such as the 6500 Series, port-channel load balancing works by assigning a hash consequence (more commonly known every bit Result Parcel Hashing, or RBH [1] ) to each member link port based on the configured hashing method. RBH tin be mapped to but ane unique physical port in the port aqueduct, but it is possible for 1 physical port to exist mapped to multiple RBH values. Likewise, the hash distribution can be based on either an adaptive or stock-still algorithm. Adaptive, the default in most systems, selectively distributes the bndl_hash among port-channel members, whereas fixed ensures fixed distribution among the members. The egress traffic hence may non hash onto the same port after the port gets flapped with the adaptive configuration.
Generally, port-channel load balancing has the following characteristics:
● It is implemented in the hardware.
● It is catamenia-based only not bandwidth-based.
● Information technology is an ingress feature that takes effect in the egress.
● For a given flow, the RBH ever remains the same.
Due to the higher up, it is obvious that RBH multifariousness plays a disquisitional role in how flows tin can exist evenly distributed across all the links. This RBH diversity is dependent on the traffic diversity, meaning the more diverse the traffic is, the more evenly the flows would be distributed. For example, if a port-channel consists of eight 10G links, and if the traffic flows are non various enough, virtually of the traffic would exist hashed to i single link. This could potentially cause packets to be dropped if that particular link is well-nigh its capacity while the remaining links are however largely unused.
In the Cisco Goad 9000 family, a slightly different algorithm is used, where four polynomials are supported for the hash digest. The hash key length is 512 bits, and it yields ii 6-bit hash values that range from 0x0 to 0x63. However, this does non necessarily mean that 64 member links tin can be supported in a port channel. In fact, only a maximum of 16 member links are supported per port aqueduct (simply 8 are active). Information technology is recommended that you always refer to the release notes for the latest data.
In Catalyst 9000 series, based on the source and mac address (it can likewise be based on ipv4 address, port or vlan) of a particular stream, the following command can be used to summate and show the destination port that will be selected.
C9300#show platform software fed switch {switch_num | active | standby} etherchannel channel-grouping-number load-balance mac src_mac dst_mac

Platform throughput
For platform throughput, it is obvious that there should non be any choke betoken in the network. In IP video surveillance networks, it is common to accept intelligent video systems that perform synchronization and backfilling (syncing and resending lost data from the local HDD to the storage system via a unicast stream). Hence, if a platform's throughput is X, the aggregate traffic volume should non exist designed to the most range of X. Instead, a buffer of at to the lowest degree 10 to xv pct should e'er be factored in should unicast or other unicast applications cause the traffic surge.
CPU queue limit
The CPU queue limit differs from platform to platform. A quick way to meet whether this value is appropriate is to use the "bear witness CPU" control and monitor whether the CPU is always on the high side. Another way to monitor is via the post-obit command to see if there is any drop on the interfaces.
C9300#show platform hardware fed switch agile qos queue stats interface <blazon number>
Core layer system design with StackWise Virtual
Cisco StackWise Virtual, replacing its predecessor Virtual Switching System (VSS), is a network system virtualization applied science that pairs two Cisco Catalyst 9000 family switches into a single logical network entity from the network command and management perspective. It uses SSO and Nonstop Forwarding (NSF) of routing protocols to provide seamless traffic failover when ane of the devices in a StackWise domain fails. Within a domain, one device is designated as active and the other as standby. All command-plane functions are managed by the agile switch, just from a data-airplane perspective, both switches in the domain actively forward the traffic. Besides yielding all the benefits of VSS, StackWise Virtual likewise simplifies connexion by connecting upwards switches' fixed forepart-console ports using either 10G or 40G ports.
A detailed description of StackWise Virtual can be found at: https://www.cisco.com/c/en/us/td/docs/switches/lan/catalyst9500/software/release/xvi-6/configuration_guide/b_166_ha_9500/b_166_ha_9500_chapter_01.html.
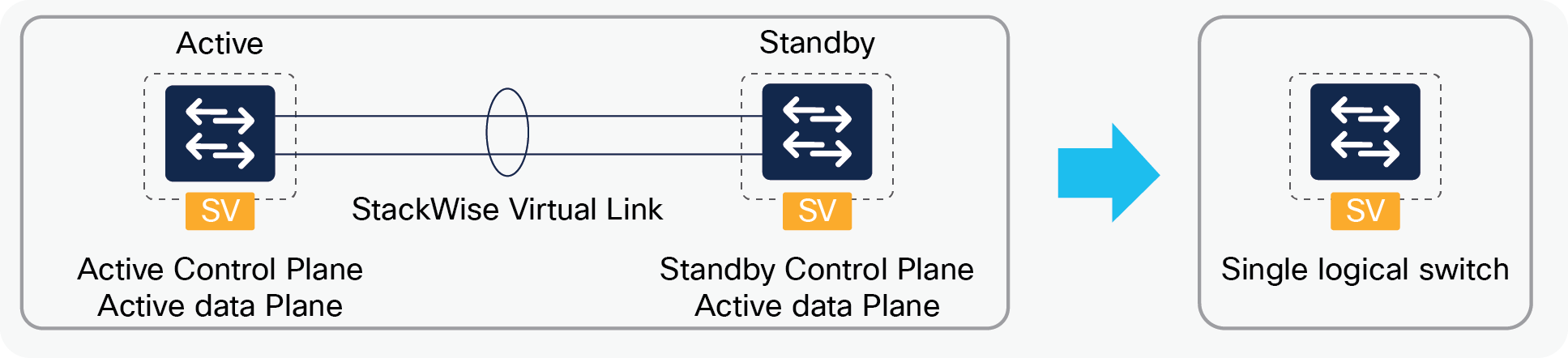
Effigy 1.
StackWise Virtual
The Cisco Catalyst 9600 and 9500 Series are all-time-in class next-generation switching platforms to be deployed in both the core and distribution layers. The 9300 and 9400 Series were likewise tested in the distribution layer, but due to the lack of port density in the 9300 Series and the StackWise limitation on the 9400 Series, the 9500 Series was selected. The 9600 Series can exist used in either the cadre or distribution layer, and due to its newer hardware design, it is logical to expect that its performance will be better than that of the 9500 Series.
Two architectures are commonly used with StackWise Virtual.
Design option 1
In the first pattern option, the Cisco Catalyst 9000 family is deployed for both the core and distribution layers. The logical topology in Figure 2 shows a high-level compages that deploys StackWise Virtual in both the core and distribution layers. This is a straightforward and elementary architecture. It can also exist tweaked to accommodate larger mroute scales by inserting another pair of core devices to distribute the traffic.
Pattern choice 2
This option uses a slightly contradistinct architecture. Although the three-tier model remains, the network is now segmented into four different blocks, with each all-around a few thousand multicast streams, depending on the need. Assuming that 10,000 multicast streams are required, a block is designed to incorporate 2500 multicast streams. These four blocks are and so interconnected to the key monitoring systems where operators and video systems are hosted. The master reason for this segmentation is to obtain a smaller mistake domain command, in dissimilarity to design option 1, where the whole network blacks out if the cadre suffers a catastrophic impact.
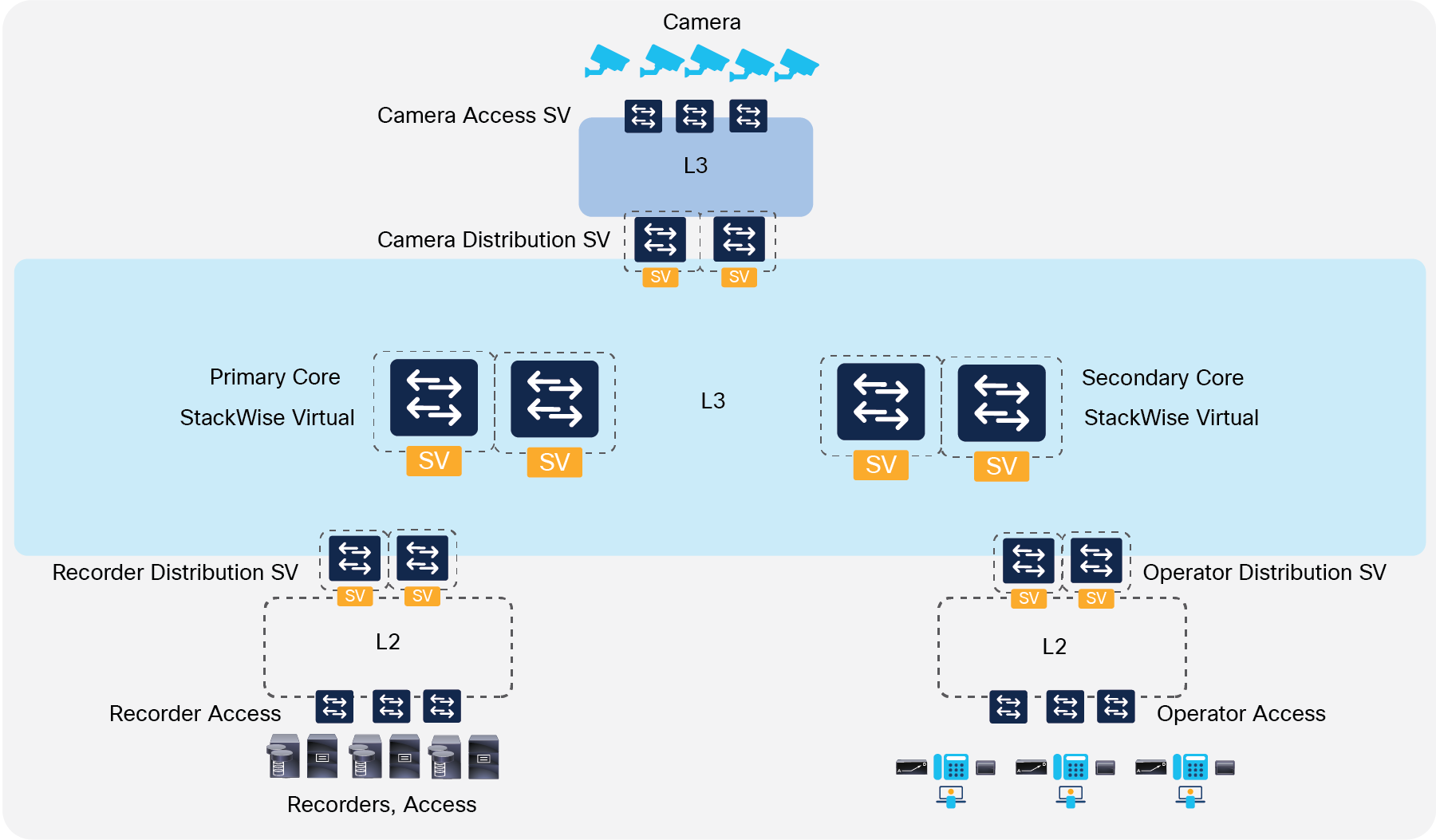
Figure two.
Design option 1: StackWise Virtual in a 3-tier architecture

Figure 3.
Design option 2: StackWise Virtual in blocks
Key design considerations
The post-obit sections describe some major central pattern considerations in achieving fast multicast convergence, error tolerance, and scalability in IP multicast video surveillance networks.
MEC
● Although rare, in the issue that only a unmarried link in MEC remains, that single link must be designed in such a way that it will exist able to accept upward the aggregate load from both the downstream and upstream routers and switches. This is to ensure the highest SLA for mistake tolerance.
● In the Cisco Goad 9000 family, although the RBH uses 6-bit hash values, port-channel hashing should still exist tested to ensure that the multicast addressing scheme does not unintentionally hash almost of the multicast traffic to a detail link.
Cadre layer architecture
● The Cisco Catalyst 9500 Series is used to form the StackWise Virtual domain for the core layer. Every bit the 9500 Series has only a maximum of forty-eight 10G ports or twenty at 40G density, it is suitable for a smaller individual cake environment where but 2000 to 3000 multicast cameras are deployed. For larger domains, the Cisco Catalyst 9600 Series should be considered for its higher port density and amend performance.
● The Cisco Catalyst 9000 family, especially when comparing to the end-of-life 6500 Series, provides 7.5 times more than throughput per slot, 3 times the port density of 40G, and 4 times the CPU capability, with no oversubscription. This is made possible by the Cisco Unified Admission ® Data Plane (UADP) 3.0 next-generation network application-specific integrated excursion (NGN ASIC), and all these factors contribute to both fast convergence and fault tolerance.
Camera access layer compages
● A routed admission model is used here, since the bulk of IP video cameras have just a single network port.
● Due to the requirement for high 1G port density, the Cisco Catalyst 9400 Series with two supervisor engines tin be used here to provide in-chassis back-up, instead of StackWise Virtual. The maximum 1G port density for the 9410R is 48 x 8 = 384 ports. In the testing environment, ii 9400 Series switches were used to connect to Spirent transmitter ports.
Camera distribution, recorder/storage distribution layer architecture
● Cisco Goad 9500 Series Switches are deployed as distribution switches for both photographic camera and storage. Assuming that a multicast stream is 6 Mbps, 2500 multicast cameras volition generate roughly 15 Gbps traffic. A unmarried pair of 9500 Serial switches forming a StackWise Virtual domain is sufficient to amass all the traffic from all the camera access switches. The same calculation goes for the storage distribution switches.
Operator distribution
● The operator distribution switch or switches are placed in a split up segment to interconnect all the individual blocks. This is necessary because the operators, as well equally the video surveillance systems, will need to exist able to access all the cameras, recording servers, and storage systems. Depending on the number of operators and the sizing of the video systems, more than a pair of operator distribution switches operating in StackWise Virtual can exist deployed. The bandwidth for the uplinks from the operator distribution switches depends on the monitoring needs. Assuming that one operator has a need to view footage from 40 cameras on his or her screen at 1 time, this translates to 6 Mbps x 40 = 240 Mbps per operator. With this calculation, the uplinks can easily be determined. In this test topology, four 10G uplinks are used to connect the operator distribution StackWise Virtual domain to the core StackWise Virtual domain of each block.
● Although it is possible to configure merely a single RP on the operator distribution pair or to configure a dedicated RP cluster [2] connected to the operator distribution pair for a simpler architecture, in the unlikely event that the RP is isolated from all the individual blocks, the multicast operations in each individual cake will fail. [3] Therefore, if fault tolerance is a high priority, besides configuring the RP with anycast on the operator distribution pair, a separate RP is also configured on the core of each block. The RP on the distribution pair and then establishes interdomain MSDP peering with all other RPs configured on every block's core to exchange active multicast source information. An egress SA filter is put in identify to allow merely operator distribution active sources to be advertised to all the other blocks. An ingress filter should also exist configured, if possible, to restrict multicast source ranges from every block.
● The most important affair to note here is that depending on the full number of mroutes, a dissimilar architectural approach or the correct platform for operator distribution should be selected.
Storage/operator access architecture
● The access layer terminates the recording servers and operator stations. Either a Cisco Catalyst 3850 or 9400 Series switch can be deployed here if college port density is required. If a 3850 Series switch is deployed, StackWise-480 tin be used, and for the 9400 Series, [iv] StackWise Virtual tin can be deployed, although generally the 9400 Series is a better choice from both the hardware and software perspectives. If port density is not a business concern, a Cisco Catalyst 9500 Series Switch with StackWise Virtual tin also exist considered.
In-Service Software Upgrade (ISSU)
● StackWise Virtual also supports ISSU. This feature helps to avoid network service outages when performing upgrades, downgrades, or rollbacks of Cisco IOS XE software.
End-to-end characterized IP video surveillance results
Spirent was used as both traffic transmitters and receivers in this case, with no real end devices continued to the network. It was configured to generate up to 10,000 multicast groups, with each photographic camera sending to one unique multicast group. A subset of exam items were executed, with the master focus on the multicast traffic failover and convergence, including:
● Chassis
● Line card
● EtherChannel links
● StackWise Virtual link (SVL)
As shown in Table 1, the test results for design option 1 (without secondary core) demonstrated that subsecond convergence for multicast traffic is possible nether virtually of the failure scenarios. Choice ii result is not listed here as it is like to option 1 from design perspective, with the main exception that it is segmented into more smaller fault domains.
Tabular array 1. Design choice 1:- StackWise Virtual examination results
| Applied science in use: StackWise Virtual | |||
| Item | Test case | Loss time (s) | Note |
| 1 | Frequent multicast join/exit (10,000 on Core) | Y | As expected |
| ii | Principal core SW-1 active failure | Y | As expected due to StackWise Virtual mechanism |
| 3 | Traffic disruption observed on operator distribution | Y | As expected |
| 4 | Master core SW-2 (now agile) failure | Y | As expected |
| v | StackWise Virtual link single-link failure | Y | As expected; affected only data traffic that used StackWise Virtual link to go to its peer |
| 6 | StackWise Virtual link total failure | Y | As expected; the original standby switch transitions to become an active virtual switch per dual-agile detection mechanism |
| seven | Primary cadre SW-1 link failure toward recorder distribution | Y | As expected; this is the time taken to find the link failure and readjust the load-balancing algorithm |
| 8 | Camera distribution SW-1 active failure | Y | As expected |
| nine | Camera distribution StackWise Virtual Link failure | Y | As expected |
| 10 | Camera distribution to primary core EtherChannel link failure | Y | Every bit expected |
Observations
StackWise Virtual works as expected to evangelize subsecond convergence for multicast traffic. However, the following need to be heeded in the pattern:
● StackWise Virtual works every bit expected, with much amend operation than the stop-of-life VSS in the Cisco Catalyst 6500 Series. The operation is also simpler compared to VSS from the perspective of the congenital-in dual-active detection mechanism.
● ECMP improves the multicast failover convergence time. This is expected considering when a chassis in a StackWise Virtual domain went downwards, only the multicast traffic flowing through that chassis needed to fail over. In an ideal instance, only 50 percent of the multicast traffic needs to fail over, and hence the time to reconverge is shorter. If the amount of multicast flow is only tens or hundreds, configuring ECMP may non produce any significant improvement.
● For blueprint option 2, a slight filibuster (on the monitoring screen) may exist observed when an operator tries to access the cameras while failover is happening at the individual block'southward core. This can be improved by tuning relevant MSDP parameters, such as the sa-interval.
● Similar to design choice 1, if the core in the block fails in design option 2, that particular block blacks out, although with a much smaller fault domain.
● Operator distribution, on the other paw, needs to always be up if the operators are required to access the cameras and recorders with no service downtime. This is a debatable gray area because theoretically, even if the operator distribution switches are downwards, the recordings will non exist affected in any way. However, the local regulations may regard that as a blackout if the operators lose access to real-fourth dimension monitoring.
● MEC: With 64-scrap RBH, multicast traffic flows are more evenly distributed across different port-channel member links. However, with this undersubscribed model, it is non an issue, as even a single link could arrange the total load of multicast traffic.
● Note that the test results as described here might vary with the hardware and software in use, also as the configuration.
Conclusion
From the blueprint options described in a higher place, it is obvious that multicast subsecond convergence, fault tolerance, and scalability for an IP multicast video surveillance network can be achieved nether near circumstances with StackWise Virtual configurations.
Although there are other possible emerging architectures, such as Clos, StackWise Virtual is a natural recommended pick for the next few years due to its stability and maturity.
Reference
i. High Availability Configuration Guide, Cisco IOS XE Everest xvi.six.x: https://www.cisco.com/c/en/united states/td/docs/switches/lan/catalyst9500/software/release/sixteen-six/configuration_guide/b_166_ha_9500/b_166_ha_9500_chapter_01.html
2. IP Multicast Technology Overview: https://www.cisco.com/c/en/united states of america/td/docs/ios/solutions_docs/ip_multicast/White_papers/mcst_ovr.html
Source: https://www.cisco.com/c/en/us/solutions/collateral/enterprise-networks/white-paper-c11-743810.html
Posted by: domingonathe1986.blogspot.com
0 Response to "How To Use Multicast With Ip Cameras"
Post a Comment